
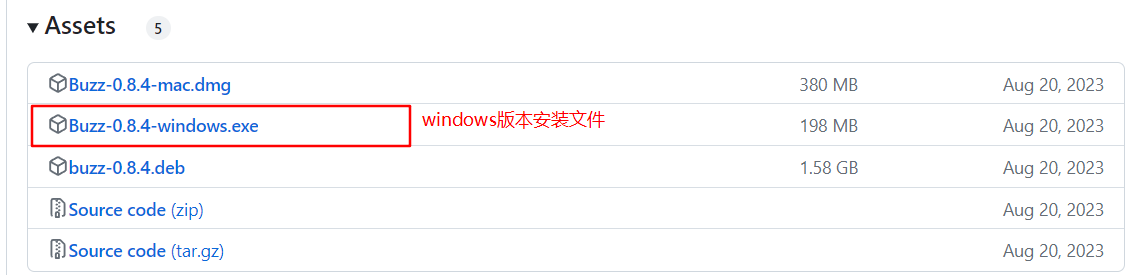
官网地址
https://github.com/chidiwilliams/buzz/releases
基于OpenAI Whisper。提供一个图形化界面使用
有时候想把会议的录音转换成文字,就有了这个需求。于是在网上找了一下现成的,发现也有不少,而这款看介绍用起来是最适合非技术人员的。就用这个。
优点:
- 离线模型
- 可根据不同的质量要求使用不同的模型
使用方式
首先在官网下载适合自己操作系统的安装文件,安装到本机。
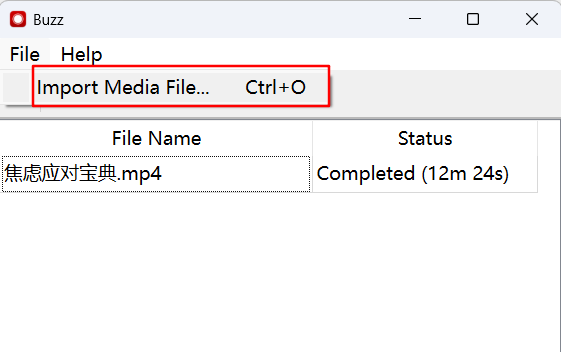
安装完成,可以导入要转换的音视频文件。支持音频,也支持视频。
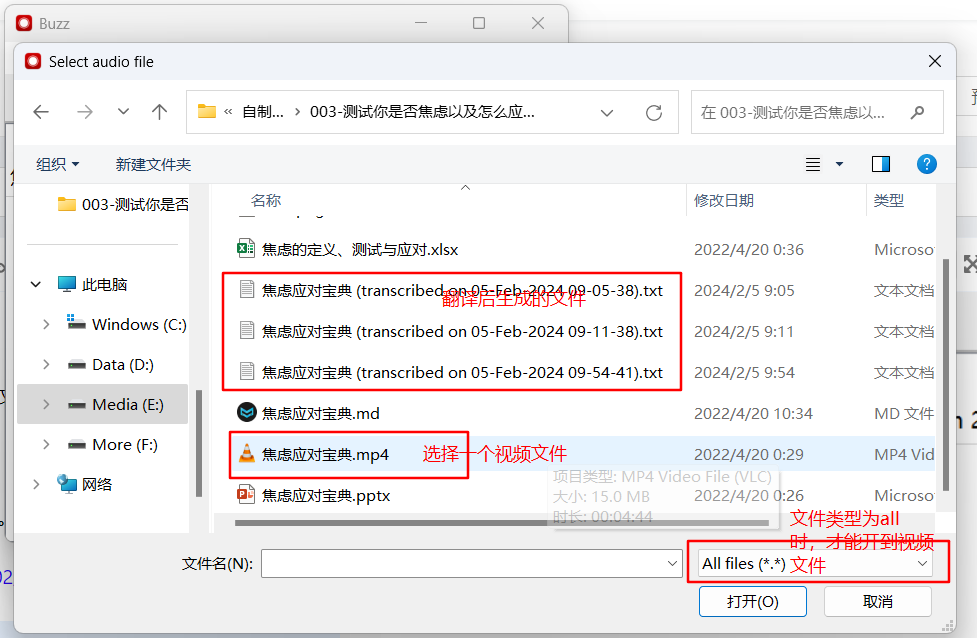
选择对应的模型和语言。我这里选择了medium模型,模型不存在的话,会下载模型(此时需要联网)。我尝试了tiny模型和medium模型。发现随着模型文件的增大,转换质量有着质的提升。
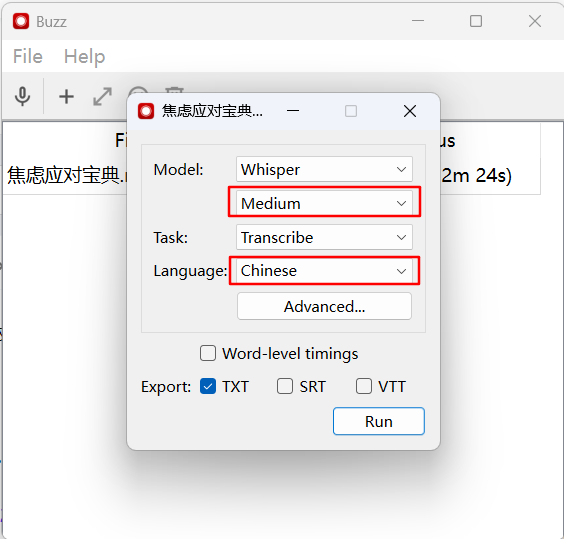
然后点击run就等待结果完成就可以了。
下载的模型默认存储地址
实践证明把文件放在指定的位置,即认为是下载好的。另外1.0.1版本把large版本分成了large-v2,large-v3。0.8.4版本的large即位large-v2。large-v3太大了,没下载。
0.8.4 版本
- C:\Users${your_user_name}.cache\whisper
1.0.1 版本
- C:\Users${your_user_name}\AppData\Local\Buzz\Buzz\Cache\models\whisper